
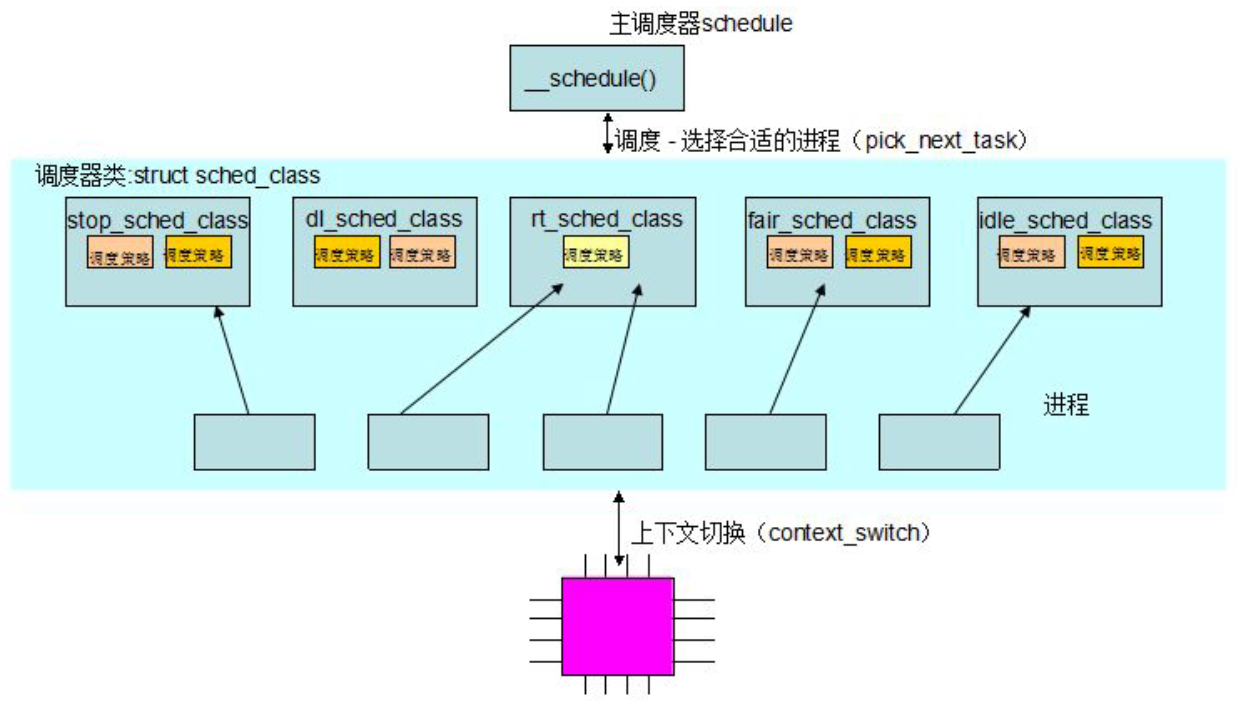
##2.进程调度 内核调度模块示意图如下所示
###2.1调度策略 当进程被调用时选择以下策略中的一种:
SCHED_NORMAL(SCHED_OTHER):普通的分时进程
SCHED_FIFO:先入先出的实时进程
SCHED_RR:时间片轮转的实时进程
SCHED_BATCH:用于非交互,CPU使用密集型的批处理进程
SCHED_IDLE:只在系统空闲时才能够被调度执行的进程
###2.2调度类
调度类的引入增强了内核调度程序的可扩展性,这些类(调度程序模块)封装了调度策略并将调度策略模块化。着重讲解下面两个调度类,其他调度类以后补充
-
CFS调度类(在kernel/sched/fair.c中实现)用于: 调度策略: SCHED_NORMAL、 SCHED_BATCH和SCHED_IDLE
-
实时调度类(在kernel/sched/rt.c中实现)用于: 调度策略: SCHED_RR和SCHED_FIFO策略
pick_next_task:选择下一个要运行的进程
###2.3进程优先级 在struct task_struct中有三个成员来表示进程的优先级如下:
int prio, static_prio, normal_prio;
static_prio:表示进程的静态优先级、是进程启动时候设置的优先级。
normal_prio:基于static_prio和调度策略计算出的优先级。
prio:调度器采用的优先级,内核有些时候需要暂时提高某个进程的优先级,因为这个改变是临时的,所以内核使用了第三个变量表示临时优先级。
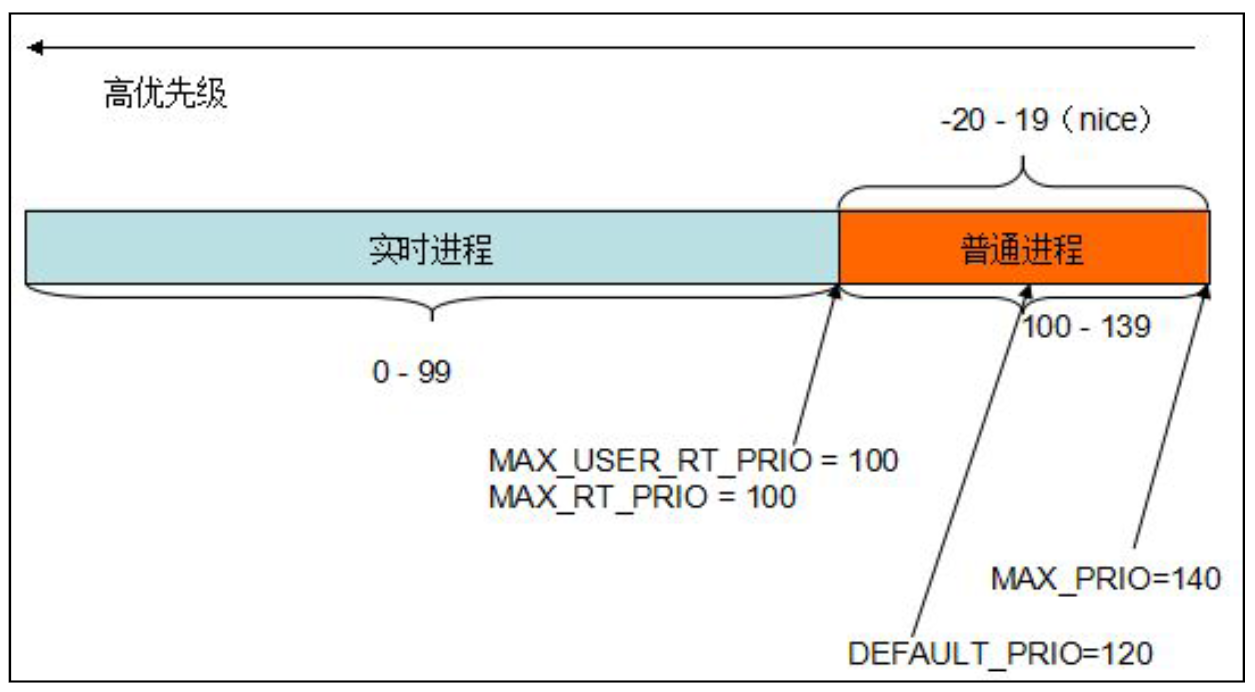
内核优先级宏定义:
#define MAX_NICE 19
#define MIN_NICE -20
#define NICE_WIDTH (MAX_NICE - MIN_NICE + 1) //=40
#define MAX_USER_RT_PRIO 100
#define MAX_RT_PRIO MAX_USER_RT_PRIO
#define MAX_PRIO (MAX_RT_PRIO + NICE_WIDTH) //=140
#define DEFAULT_PRIO (MAX_RT_PRIO + NICE_WIDTH / 2)
上面的定义是基于下面这张示意图:
内核计算优先级的函数:
kernel/sched/core.c
static int effective_prio(struct task_struct *p)
{
p->normal_prio = normal_prio(p);
/*
* If we are RT tasks or we were boosted to RT priority,
* keep the priority unchanged. Otherwise, update priority
* to the normal priority:
*/
if (!rt_prio(p->prio))
return p->normal_prio;
return p->prio;
}
normal_prio:基于static_prio和调度策略计算出的优先级。所以内核的normal_prio正常优先级计算函数为:
static inline int normal_prio(struct task_struct *p)
{
int prio;
if (task_has_dl_policy(p)) (1)
prio = MAX_DL_PRIO-1;
else if (task_has_rt_policy(p)) (2)
prio = MAX_RT_PRIO-1 - p->rt_priority;
else
prio = __normal_prio(p); (3)
return prio;
}
static inline int __normal_prio(struct task_struct *p)
{
return p->static_prio;
}
(1)(2)(3)可知内核是通过判断不同的调度策略赋予normal_prio不同的值,这也印证了我们对normal_prio的定义:基于static_prio和调度策略计算出的优先级。
###2.4调度时机 调度什么时候发生?即:schedule()函数什么时候被调用?
调度的发生有两种方式:
-
主动式
在内核中直接调用schedule()调度函数,当进程需要等待资源等而暂时停止运行时,会把状态置于挂起(睡眠),并主动请求调度,让出CPU。 主动放弃cpu例:
(1) current->state = TASK_INTERRUPTIBLE;
(2) schedule();
-
被动式(抢占)
用户抢占(Linux2.4、Linux2.6)
内核抢占(Linux2.6)
用户抢占发生在:
从系统调用(内核)返回用户空间。
从中断处理程序返回用户空间。
内核即将返回用户空间的时候,如果need_resched标识被设置,会导致schedule()被调用,此时就会发生用户抢占。
内核抢占发生在:
在不支持内核抢占的系统中,进程/线程一旦运行于内核空间,就可以一直运行,直到它主动放弃或时间片耗尽为止。这样一些非常紧急的进程或线程将长时间得不到运行。在支持内核抢占的系统中,更高优先级的进程/线程可以抢占正在内核空间运行的低优先级进程/线程。
在支持内核抢占的系统中,某些特例下是不允许内核抢占的:
- 内核正进行中断处理。进程调度函数schedule()会对此做出判断,如果是在中断中调用,会打印错误信息。
- 内核正在进行中断上下文的Bottom Half(中断的底半部)处理。硬件中断返回前会执行软中断,此时仍然处于中断上下文中。
- 进程正持有spinlock自旋锁、writelock/readlock读写锁等,当持有这些锁时,不应该被抢占,否则由于抢占将导致其他CPU长期不能获得锁而死等。 内核正在执行调度程序scheduler。抢占的原因就是为了进行新的调度,没有理由将调度程序抢占掉再运行调度程序。
为保证Linux内核在以上情况下不会被抢占,抢占式内核使用了一个preempt_count变量,称为内核抢占计数。这一变量被设置在进程的thread_info结构中。每当内核要进入以上几种状态时,变量preempt_count就加1,指示内核不允许抢占。每当内核从以上几种状态退出时,变量preempt_count就减1,同时进行可抢占的判断与调度。
内核抢占可能发生在:
- 中断处理程序完成,返回内核空间之前。
- 当内核代码再一次具有可抢占性的时候,如解锁及使能软中断等。
调度标识
TIF_NEED_RESCHED
作用:
内核提供一个need_resched标识来表明是否需要重新执行一次调度。
设置:
当某个进程需要放弃CPU的时候,会设置这个标识;
当一个优先级更高的进程进入可执行状态的时候,也会设置这个标识。
###2.5调度步骤 ####内核最主要的调度函数:__schedule
static void __sched __schedule(void)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq *rq;
int cpu;
need_resched:
preempt_disable();
cpu = smp_processor_id();
rq = cpu_rq(cpu);
rcu_note_context_switch();
prev = rq->curr;
schedule_debug(prev);
if (sched_feat(HRTICK))
hrtick_clear(rq);
/*
* Make sure that signal_pending_state()->signal_pending() below
* can't be reordered with __set_current_state(TASK_INTERRUPTIBLE)
* done by the caller to avoid the race with signal_wake_up().
*/
smp_mb__before_spinlock();
raw_spin_lock_irq(&rq->lock);
switch_count = &prev->nivcsw;
if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) {
if (unlikely(signal_pending_state(prev->state, prev))) {
prev->state = TASK_RUNNING;
} else {
deactivate_task(rq, prev, DEQUEUE_SLEEP);
prev->on_rq = 0;
/*
* If a worker went to sleep, notify and ask workqueue
* whether it wants to wake up a task to maintain
* concurrency.
*/
if (prev->flags & PF_WQ_WORKER) {
struct task_struct *to_wakeup;
to_wakeup = wq_worker_sleeping(prev, cpu);
if (to_wakeup)
try_to_wake_up_local(to_wakeup);
}
}
switch_count = &prev->nvcsw;
}
if (task_on_rq_queued(prev) || rq->skip_clock_update < 0)
update_rq_clock(rq);
next = pick_next_task(rq, prev); (1)
clear_tsk_need_resched(prev);
clear_preempt_need_resched();
rq->skip_clock_update = 0;
if (likely(prev != next)) {
rq->nr_switches++;
rq->curr = next;
++*switch_count;
rq = context_switch(rq, prev, next); /* unlocks the rq */ (2)
cpu = cpu_of(rq);
} else
raw_spin_unlock_irq(&rq->lock);
post_schedule(rq);
sched_preempt_enable_no_resched();
if (need_resched()) (3)一个很微妙的问题!!!
goto need_resched;
}
schedule函数工作流程如下:
-
选择下一个要运行的进程;(pick_next_task分析)
/* * Pick up the highest-prio task: */ static inline struct task_struct * pick_next_task(struct rq *rq, struct task_struct *prev) { const struct sched_class *class = &fair_sched_class; struct task_struct *p; /* * Optimization: we know that if all tasks are in * the fair class we can call that function directly: */ if (likely(prev->sched_class == class && rq->nr_running == rq->cfs.h_nr_running)) { p = fair_sched_class.pick_next_task(rq, prev); if (unlikely(p == RETRY_TASK)) goto again; /* assumes fair_sched_class->next == idle_sched_class */ if (unlikely(!p)) p = idle_sched_class.pick_next_task(rq, prev); return p; } //注意以上代码片段为优化,因为我们知道CFS是普通进程的调度类,而系统中绝大多数进程都是普通进程,当系统中所有运行的进程数量等于CFS类所对应的可运行进程的数量的时候,我们就直接调用CFS的pick_next_task函数来选择下一个可运行的进程。 again: //轮训系统中的调度类,它以优先级为序,从最高的优先级开始到fair_sched_class。 for_each_class(class) { p = class->pick_next_task(rq, prev); //如下图所示的遍历优先级顺序。 if (p) { if (unlikely(p == RETRY_TASK)) goto again; return p; } } BUG(); /* the idle class will always have a runnable task */ }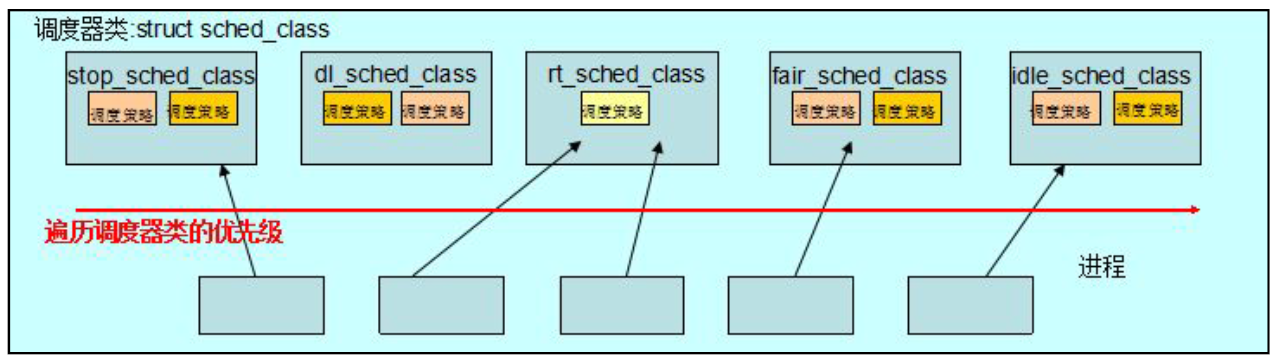
-
进程上下文切换。
从一个可执行进程切换到另一个可执行的进程:
/* * context_switch - switch to the new MM and the new thread's register state. */ static inline struct rq * context_switch(struct rq *rq, struct task_struct *prev, struct task_struct *next) { struct mm_struct *mm, *oldmm; prepare_task_switch(rq, prev, next); mm = next->mm; oldmm = prev->active_mm; /* * For paravirt, this is coupled with an exit in switch_to to * combine the page table reload and the switch backend into * one hypercall. */ arch_start_context_switch(prev); if (!mm) { next->active_mm = oldmm; atomic_inc(&oldmm->mm_count); enter_lazy_tlb(oldmm, next); } else switch_mm(oldmm, mm, next); //切换进程的虚拟内存空间,也就是切换进程的页表。 if (!prev->mm) { prev->active_mm = NULL; rq->prev_mm = oldmm; } /* * Since the runqueue lock will be released by the next * task (which is an invalid locking op but in the case * of the scheduler it's an obvious special-case), so we * do an early lockdep release here: */ spin_release(&rq->lock.dep_map, 1, _THIS_IP_); context_tracking_task_switch(prev, next); /* Here we just switch the register state and the stack. */ switch_to(prev, next, prev); //从上一个处理器状态切换到下一个处理器状态,保存上一个进程CPU寄存器信息到该进程的内核栈,从下一个进程的内核栈中装载CPU寄存器信息。 barrier(); return finish_task_switch(prev); } -
一个很微妙的问题
if (need_resched()) (3)一个很微妙的问题!!! goto need_resched;执行完
swtich_to函数后,就调度成功了。need_resched()是调度的尾声,可以被抢占要注意这个代码段,此时此段代码:
- 如果进程没有发生切换,那么他就在当前被调度进程的上下文中运行。
- 如果进程有发生切换,那么上一个进程在执行到第二步的时候就已经被调度出去了,此时新的进程已经接管了CPU了,所以这段代码就执行在新的进程的上下文了。
当被调度的进程被重新选择运行的时候,此时他会在这个点上开始接着运行,所以此时的代码段又执行在上一个被调度进程的上下文中了。